
Объяснение SQL объединений JOIN: LEFT/RIGHT/INNER/OUTER
Категория: / DEV Блог
/ PHP (LAMP)
Разберем пример. Имеем две таблицы: пользователи и отделы.
Запрос вернет объединенные данные, которые пересекаются по условию, указанному в INNER JOIN ON <..>.
В нашем случае условие <таблица_пользователей>.<идентификатор_отдела> должен совпадать с <таблица_отделов>.<идентификатор>
В результате отсутствуют:
- пользователь Александр (отдел 6 - не существует)
- отдел Финансы (нет пользователей)
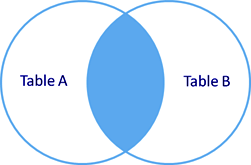
рис. Inner join
Внутреннее объединение INNER JOIN (синоним JOIN, ключевое слово INNER можно опустить).
Выбираются только совпадающие данные из объединяемых таблиц.
Чтобы получить данные, которые подходят по условию частично, необходимо использовать
внешнее объединение - OUTER JOIN.
Такое объединение вернет данные из обеих таблиц (совпадающие по условию объединения) ПЛЮС дополнит выборку оставшимися данными из внешней таблицы, которые по условию не подходят, заполнив недостающие данные значением NULL.
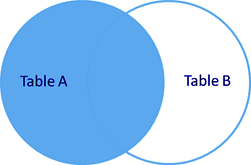
рис. Left join
Существует два типа внешнего объединения OUTER JOIN - LEFT OUTER JOIN и RIGHT OUTER JOIN.
Работают они одинаково, разница заключается в том что LEFT - указывает что "внешней" таблицей будет находящаяся слева (в нашем примере это таблица users).
Ключевое слово OUTER можно опустить. Запись LEFT JOIN идентична LEFT OUTER JOIN.
Получаем полный список пользователей и сопоставленные департаменты.
Добавив условие
в выборке останется только 3#Александр, так как у него не назначен департамент.
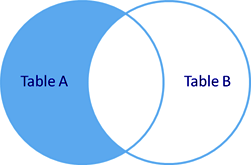
рис. Left outer join с фильтрацией по полю
RIGHT OUTER JOIN вернет полный список департаментов (правая таблица) и сопоставленных пользователей.
Дополнительно можно отфильтровать данные, проверяя их на NULL.
В нашем примере указав WHERE u.id IS null, мы выберем департаменты, в которых не числятся пользователи. (3#Финансы)
Все примеры вы можете протестировать здесь:
SQLFiddle
Cross/Full Join
FULL JOIN возвращает `объединение` объединений LEFT и RIGHT таблиц, комбинируя результат двух запросов.
CROSS JOIN возвращает перекрестное (декартово) объединение двух таблиц. Результатом будет выборка всех записей первой таблицы объединенная с каждой строкой второй таблицы. Важным моментом является то, что для кросса не нужно указывать условие объединения.
Дублирование строк при использовании JOIN
При использовании объединения новички часто забывают что результирующая выборка может содержать дублирующиеся данные!
Если вам нужна одна запись, делайте объединение с подзапросом
Self Join
Выборка из одной и той же таблицы для нескольких условий.
Рассмотрим задачку от яндекса:
Есть таблица товаров.
Она содержит следующие значения.
Напишите запрос, выбирающий уникальные пары `id` товаров с одинаковыми `name`, например:
(1,2), (4,1), (2,4), (6,3)...
При решении задачи необходимо учесть, что пары (x,y) и (y,x) — одинаковы.
Решение:
Объединяем таблицы ya_goods по одинаковому полю `name`, группируем по уникальным idентификаторам и получаем результат.
(1,2)(1,4)(2,4)(3,6)
Множественное объединение multi join
Пригодится нам, если необходимо выбрать более одного значения из таблиц для нескольких условий.
Пример: набор вариантов (вес, объем) товаров.
Продукты в таблице products, Варианты - таблица product_options, Значения вариантов - таблица product2options
Необходимо: фильтровать продукты по дате, и имеющимся вариантам
Тестовые данные
Пример: выбрать товары,
добавленные после 17/01/2009 в следующих вариантах:
- вес=310, объем=300
- вес=35, объем=15
- вес=45, объем=25
- вес=200, объем=250
Просто перечислить условия вариантов в подзапросе/джоине через OR/AND не сработает,
необходимо осуществить объединение таблиц вариантов равное количеству этих самых вариантов (у нас - 2: объем и вес)
Результ выборки:
Этот пример на SQLFiddle
UPDATE и JOIN
Объединение можно использовать совместно с UPDATE.
Например, имеем таблицу houses (id, title, area). Нужно выбрать title, если в нем встречается `число м2`, заменить поле area, если оно меньше. Т.к. в mysql отстутсутствует поддержка регулярных выражений, нужно немного поколдовать с locate и substr.
В подзапросе выбираем интересующие нас данные, и в финальной стадии осуществляем обновление данных подходящий по критерию (p5 > area).
DELETE и JOIN
Рассмотрим пример с удалением дубликатов. Есть таблица tableWithDups (id, email). Нужно удалить строки с одинаковыми email:
Последние два примера не совместимы с ANSI SQL, но работают в mySQL.
За бортом статьи остались смежные объединениям (а также специфичные для определенных базданных темы):
SELF JOIN, FULL OUTER JOIN, CROSS JOIN (CROSS [OUTER] APPLY), операции над множествами UNION [ALL], INTERSECT, EXCEPT и т.д.
Информация по теме:
http://www.gplivna.eu/papers/sql_join_types.htm
http://blog.codinghorror.com/a-visual-explanation-of-sql-joins/
@tags: sql, mysql, sql server, oracle, sqlite, postgresql
U) users D) departments
id name d_id id name
-- ---- ---- -- ----
1 Владимир 1 1 Сейлз
2 Антон 2 2 Поддержка
3 Александр 6 3 Финансы
4 Борис 2 4 Логистика
5 Юрий 4SELECT u.id, u.name, d.name AS d_name
FROM users u
INNER JOIN departments d ON u.d_id = d.idЗапрос вернет объединенные данные, которые пересекаются по условию, указанному в INNER JOIN ON <..>.
В нашем случае условие <таблица_пользователей>.<идентификатор_отдела> должен совпадать с <таблица_отделов>.<идентификатор>
В результате отсутствуют:
- пользователь Александр (отдел 6 - не существует)
- отдел Финансы (нет пользователей)
id name d_name
-- -------- ---------
1 Владимир Сейлз
2 Антон Поддержка
4 Борис Поддержка
3 Юрий Логистикарис. Inner join
Внутреннее объединение INNER JOIN (синоним JOIN, ключевое слово INNER можно опустить).
Выбираются только совпадающие данные из объединяемых таблиц.
Чтобы получить данные, которые подходят по условию частично, необходимо использовать
внешнее объединение - OUTER JOIN.
Такое объединение вернет данные из обеих таблиц (совпадающие по условию объединения) ПЛЮС дополнит выборку оставшимися данными из внешней таблицы, которые по условию не подходят, заполнив недостающие данные значением NULL.
рис. Left join
Существует два типа внешнего объединения OUTER JOIN - LEFT OUTER JOIN и RIGHT OUTER JOIN.
Работают они одинаково, разница заключается в том что LEFT - указывает что "внешней" таблицей будет находящаяся слева (в нашем примере это таблица users).
Ключевое слово OUTER можно опустить. Запись LEFT JOIN идентична LEFT OUTER JOIN.
SELECT u.id, u.name, d.name AS d_name
FROM users u
LEFT OUTER JOIN departments d ON u.d_id = d.idПолучаем полный список пользователей и сопоставленные департаменты.
id name d_name
-- -------- ---------
1 Владимир Сейлз
2 Антон Поддержка
3 Александр NULL
4 Борис Поддержка
5 Юрий ЛогистикаДобавив условие
WHERE d.id IS NULLв выборке останется только 3#Александр, так как у него не назначен департамент.
рис. Left outer join с фильтрацией по полю
RIGHT OUTER JOIN вернет полный список департаментов (правая таблица) и сопоставленных пользователей.
SELECT u.id, u.name, d.name AS d_name
FROM users u
RIGHT OUTER JOIN departments d ON u.d_id = d.idid name d_name
-- -------- ---------
1 Владимир Сейлз
2 Антон Поддержка
4 Борис Поддержка
NULL NULL Финансы
5 Юрий ЛогистикаДополнительно можно отфильтровать данные, проверяя их на NULL.
SELECT d.id, d.name
FROM users u
RIGHT OUTER JOIN departments d ON u.d_id = d.id
WHERE u.id IS nullВ нашем примере указав WHERE u.id IS null, мы выберем департаменты, в которых не числятся пользователи. (3#Финансы)
Все примеры вы можете протестировать здесь:
SQLFiddle
Cross/Full Join
FULL JOIN возвращает `объединение` объединений LEFT и RIGHT таблиц, комбинируя результат двух запросов.
CROSS JOIN возвращает перекрестное (декартово) объединение двух таблиц. Результатом будет выборка всех записей первой таблицы объединенная с каждой строкой второй таблицы. Важным моментом является то, что для кросса не нужно указывать условие объединения.
Дублирование строк при использовании JOIN
При использовании объединения новички часто забывают что результирующая выборка может содержать дублирующиеся данные!
Если вам нужна одна запись, делайте объединение с подзапросом
SELECT t1.*, t2.* from left_table t1 left join (select * from right_table where some_column = 1 limit 1) t2 ON t1.id = t2.join_idSelf Join
Выборка из одной и той же таблицы для нескольких условий.
Рассмотрим задачку от яндекса:
Есть таблица товаров.
CREATE TABLE `ya_goods` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(64) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into ya_goods values (1, 'яблоки'), (2, 'яблоки') ,(3, 'груши'), (4,'яблоки'), (5, 'апельсины'), (6, 'груши');Она содержит следующие значения.
`id` `name`
1 Яблоки
2 Яблоки
3 Груши
4 Яблоки
5 Апельсины
6 ГрушиНапишите запрос, выбирающий уникальные пары `id` товаров с одинаковыми `name`, например:
(1,2), (4,1), (2,4), (6,3)...
При решении задачи необходимо учесть, что пары (x,y) и (y,x) — одинаковы.
Решение:
SELECT g1.id id1, g2.id id2
-- CONCAT('(', LEAST(g1.id, g2.id), ',', GREATEST(g1.id, g2.id), ')') row
FROM ya_goods g1
INNER JOIN ya_goods g2 ON g1.name = g2.name
WHERE g1.id <> g2.id
GROUP BY LEAST(g1.id, g2.id), GREATEST(g1.id, g2.id)
ORDER BY g1.id;
-- или без группировки (быстрее)
SELECT DISTINCT CONCAT('(', LEAST(g1.id, g2.id), ',', GREATEST(g1.id, g2.id), ')') row
FROM ya_goods g1
INNER JOIN ya_goods g2 ON g1.name = g2.name
WHERE g1.id <> g2.idОбъединяем таблицы ya_goods по одинаковому полю `name`, группируем по уникальным idентификаторам и получаем результат.
(1,2)(1,4)(2,4)(3,6)
Множественное объединение multi join
Пригодится нам, если необходимо выбрать более одного значения из таблиц для нескольких условий.
Пример: набор вариантов (вес, объем) товаров.
Продукты в таблице products, Варианты - таблица product_options, Значения вариантов - таблица product2options
Необходимо: фильтровать продукты по дате, и имеющимся вариантам
CREATE TABLE `products` (
`id` int(11),
`title` varchar(255),
`created_at` datetime
)
CREATE TABLE `product_options` (
`id` int(11),
`name` varchar(255)
)
CREATE TABLE `product2options` (
`product_id` int(11),
`option_id` int(11),
`value` int(11)
)Тестовые данные
INSERT INTO `products` (`id`, `title`, `created_at`) VALUES
(1, 'Кружка', '2009-01-17 20:00:00'),
(2, 'Ложка', '2009-01-18 20:00:00'),
(3, 'Тарелка', '2009-01-19 20:00:00');
INSERT INTO `product_options` (`id`, `name`) VALUES
(11, 'Вес'),
(12, 'Объем');
INSERT INTO `product2options` (`product_id`, `option_id`, `value`) VALUES
(1, 11, 200),
(1, 12, 250),
(2, 11, 35),
(2, 12, 15),
(3, 11, 310),
(3, 12, 300),
(2, 11, 45),
(2, 12, 25);Пример: выбрать товары,
добавленные после 17/01/2009 в следующих вариантах:
- вес=310, объем=300
- вес=35, объем=15
- вес=45, объем=25
- вес=200, объем=250
Просто перечислить условия вариантов в подзапросе/джоине через OR/AND не сработает,
необходимо осуществить объединение таблиц вариантов равное количеству этих самых вариантов (у нас - 2: объем и вес)
SELECT p.*, po1.name 'P1', p2o1.value, po2.name 'P2', p2o2.value
FROM products p
INNER JOIN product2options p2o1 ON p.id = p2o1.product_id
INNER JOIN product_options po1 ON po1.id = p2o1.option_id
INNER JOIN product2options p2o2 ON p.id = p2o2.product_id
INNER JOIN product_options po2 ON po2.id = p2o2.option_id
WHERE p.created_at > '2009-01-17 21:00'
AND ( -- тарелка#3
p2o1.option_id = 11 AND p2o1.value = 310
AND p2o2.option_id = 12 AND p2o2.value = 300
OR -- ложка#2
p2o1.option_id = 11 AND p2o1.value = 35
AND p2o2.option_id = 12 AND p2o2.value = 15
OR -- ложка#2
p2o1.option_id = 11 AND p2o1.value = 45
AND p2o2.option_id = 12 AND p2o2.value = 25
OR -- кружка#1 не попадает по дате
p2o1.option_id = 12 AND p2o1.value = 250
AND p2o2.option_id = 11 AND p2o2.value = 200
)
;Результ выборки:
id title created_at P1 value P2 value
2 Ложка 2009-01-18 20:00:00 Вес 35 Объем 15
3 Тарелка 2009-01-19 20:00:00 Вес 310 Объем 300
2 Ложка 2009-01-18 20:00:00 Вес 45 Объем 25
-- не попадает по дате
1 Кружка 2009-01-17 20:00:00 Объем 250 Вес 200Этот пример на SQLFiddle
UPDATE и JOIN
Объединение можно использовать совместно с UPDATE.
Например, имеем таблицу houses (id, title, area). Нужно выбрать title, если в нем встречается `число м2`, заменить поле area, если оно меньше. Т.к. в mysql отстутсутствует поддержка регулярных выражений, нужно немного поколдовать с locate и substr.
В подзапросе выбираем интересующие нас данные, и в финальной стадии осуществляем обновление данных подходящий по критерию (p5 > area).
UPDATE houses base
INNER JOIN (
-- Антарис аренда офиса 1594 м2, по ставке 12700 руб. м2/год -> 1594
SELECT
id,
@baseString := title title,
@areaTitleEnd := LOCATE(' м2', @baseString) as p2,
@tmpString := LTRIM(REVERSE(SUBSTR(@baseString, 1, @areaTitleEnd))) as p3,
@areaTitleBegin := LEFT(@tmpString, -1 + LOCATE(' ', @tmpString)) as p4,
@value := CAST(REVERSE(@areaTitleBegin) as UNSIGNED) as p5
FROM ga_pageviews
WHERE title like '%м2%'
) calc USING (`id`)
SET base.area = calc.p5
WHERE base.area < calc.p5DELETE и JOIN
Рассмотрим пример с удалением дубликатов. Есть таблица tableWithDups (id, email). Нужно удалить строки с одинаковыми email:
DELETE tableWithDups
FROM tableWithDups
INNER JOIN (
SELECT MAX(id) AS lastId, email
FROM tableWithDups
GROUP BY email
HAVING COUNT(*) > 1
) dups ON dups.email = tableWithDups.email
WHERE tableWithDups.id < dups.lastId;Последние два примера не совместимы с ANSI SQL, но работают в mySQL.
За бортом статьи остались смежные объединениям (а также специфичные для определенных базданных темы):
SELF JOIN, FULL OUTER JOIN, CROSS JOIN (CROSS [OUTER] APPLY), операции над множествами UNION [ALL], INTERSECT, EXCEPT и т.д.
Информация по теме:
http://www.gplivna.eu/papers/sql_join_types.htm
http://blog.codinghorror.com/a-visual-explanation-of-sql-joins/
@tags: sql, mysql, sql server, oracle, sqlite, postgresql
Хотелось бы и пример на SQL.
Вот это что такое p2o2 и т.д.?
Makron is bad
очень запутал такими названиями
дальше читать не интересно, лажа
u.id это users.id? или как?
FROM users u - что такое u?
что такое d.name?, u.name?, d_id?, u.d_id?, d? u?
Left Join, Right Join
Нигде не сказано, что эти таблицы ключами завязаны.
>SELECT u.id, u.name, d.name AS d_name - почему в выборке участвуют три разных столбца, но значения для столбца d_name берутся только из d.name?
Потому, что имена отделов хранятся в таблице departments.
>FROM users u - вначале эта таблица называется u, а в строке у нее уже два названия. зачем? почему?
u и d - это псевдонимы соответствующих таблиц. Для удобства написания и чтения запроса.
____________________________
Отличная статья! Наглядно, не перегруженно, с примерами применения. Хоть мне и приходилось в уме ретранслировать синтаксис в t-sql местами. :)
Спасибо!
SELECT u.id, u.name, d.name AS d_name - почему в выборке участвуют три разных столбца, но значения для столбца d_name берутся только из d.name?
FROM users u - вначале эта таблица называется u, а в строке у нее уже два названия. зачем? почему?
дальше не читала. это не инструкция а каша.
select a1.* from
(select distinct t1.id as t1_id, t2.id as t2_id from t t1
join t t2 on t1.name=t2.name
where t1.id<>t2.id) a1 join
(select distinct t3.id as t3_id, t4.id as t4_id from t t3
join t t4 on t3.name=t4.name
where t3.id<>t4.id) a2
on t1_id=t3_id and t2_id=t4_id
where (t1_id>=t4_id and t2_id<>t3_id)
order by t1_id, t2_id, t3_id, t4_id
Не знаю может тут и был. Прошу прощения. Вот мой вариант решения задачи яндекса.
SELECT g1.id id1, g2.id id2
FROM ya_goods g1
INNER JOIN ya_goods g2 ON g1.name = g2.name
WHERE g1.id < g2.id;
select * from ya_goods y1,ya_goods y2
where y1.id < y2.id and y1.name = y2.name
не?
п.с. по мне проще использовать вложенные запросы или where писать нормально, навроде
where d.id = u.id; (если id отдела имеется у юзера, можно поменять местами и сути это не изменит =) )
но главный докалупался с этими джойнами и приходится писать интуитивно непонятный запрос.
Тогда не приходится страницу вверх-вниз прокручивать, чтоб сравнивать.
SELECT u.id, u.name, d.name AS d_name FROM users u
INNER JOIN departments d ON u.d_id = d.id
Более проще, короче и понятнее будет указать
WHERE u.d_id = d.id
Дякую!
правильно, что не будет работать. Мы ищем чтоб и 3=14 и 4=15 и 6=19 одновременно. Так не бывает. Поставьте OR.
AND ( (p2.pid = 3 AND p2.value = 14) OR (p2.pid = 4 AND p2.value = 15) OR (p2.pid = 6 AND p2.value = 19) )
теперь отберутся, где 3=14 или 4=15 или 6=19
Получается одна выборка, затем отсеивание по условию. По Вашему способу придется для каждого JOIN подтягивать каждый раз таблицу.
Самое удобное что для тестов я взял XAMPP и прямо с браузера наигрался и практиковался с огромной базой данных.
Есть таблица attr (Название характеристик 238 записей) в ней поля id title
и таблица attr_goods (Значение характеристик 400.000 записей) в ней поля id_attr id_goods title
Функция ниже выводит Название характеристик-Значение характеристик, как тут www.tehno-tovar.ru/goods/4634 вкладка технические характеристики.
$id_goods - id товара
SELECT attr.title attr_title, attr_goods.title attr_goods_titl e
FROM attr
JOIN attr_goods
ON attr.id = attr_goods.id_attr
WHERE attr_goods.id_goods = $id_goods
Нужно вывести все 238 записей из таблицы attr и N количество записей из таблицы attr_goods по id_goods.
Гуру скажите, при помощи JOIN это реально.
JOIN LEFT не помогает
Готовлюсь к собеседованию, статья помогла :)
U) users
id name
1 Владимир
2 Антон
3 Александр
4 Борис
5 Юрий
D) вщдп
id d_id name
1 1 100
1 2 200
1 3 100
2 1 200
2 2 100
3 1 200
3 2 100
3 3 200
3 4 100
Нужен запрос вывода всех сотрудников и вывод сумм по d.id
В итоге иметь вот это (запрос d.id=2)
Владимир 200
Антон 100
Александр NULL
Борис NULL
Юрий NULL
Только вот тут неточность имеется: "В нашем примере указав WHERE u.id IS null, мы отбросим записи, в которых пользователи не числятся в отделах."
кроется неточность. Вернее будет так:
"В нашем примере указав WHERE u.id IS NOT null, мы отбросим записи, в которых пользователи не числятся в отделах."
или так:
"В нашем примере указав WHERE u.id IS null, мы получим отделы, в которых не числятся пользователи."
<script>alert(312)</script>
>> p1.date > '17.01.2009'
>> и дата больше заданной
???
Ваш запрос вернет выборку, в которой задействован один из фильтров, а необходимым условием является выборка со всеми параметрами фильтра.
WHERE p1.date > '17.01.2009' AND (p2.pid = 3 AND p2.value = 14) AND (p2.pid = 4 AND p2.value = 15) AND (p2.pid = 6 AND p2.value = 19)
А сделать так?
SELECT p1.title FROM products_item p1 INNER JOIN filts_data p2 ON p1.id = p2.fid
WHERE p1.date > '17.01.2009' AND ((p2.pid = 3 AND p2.value = 14) OR (p2.pid = 4 AND p2.value = 15) OR (p2.pid = 6 AND p2.value = 19))
left join = left outer join
right join = right outer join
картинка для left join правильная, для left outer join неправильная
а то голова уже болела от этих joinов
Особенно порадовала фраза "Такое объединение вернет все данные из обоих таблиц."
И картинки у вас знатные.
Авторы, хорошая трава была, а ?
ПомоглО:)